
RISC-V Integrated Processor Design with Pipelining, Cache, and Branch Prediction
Published:
Keywords: RISC-V Architecture, Advanced Pipelining, Cache Optimization, Predictive Branching, High-Performance Computing
Overview
This comprehensive project represents the culmination of three distinct yet interrelated components: a pipelined processor, a cache system, and a branch predictor. Each component was meticulously designed and tested to function both independently and as part of a unified, high-performance processor architecture. The following sections detail the integrated design, showcasing the synergy between the processor pipeline, cache subsystem, and branch prediction unit.
Processor Pipeline
Design
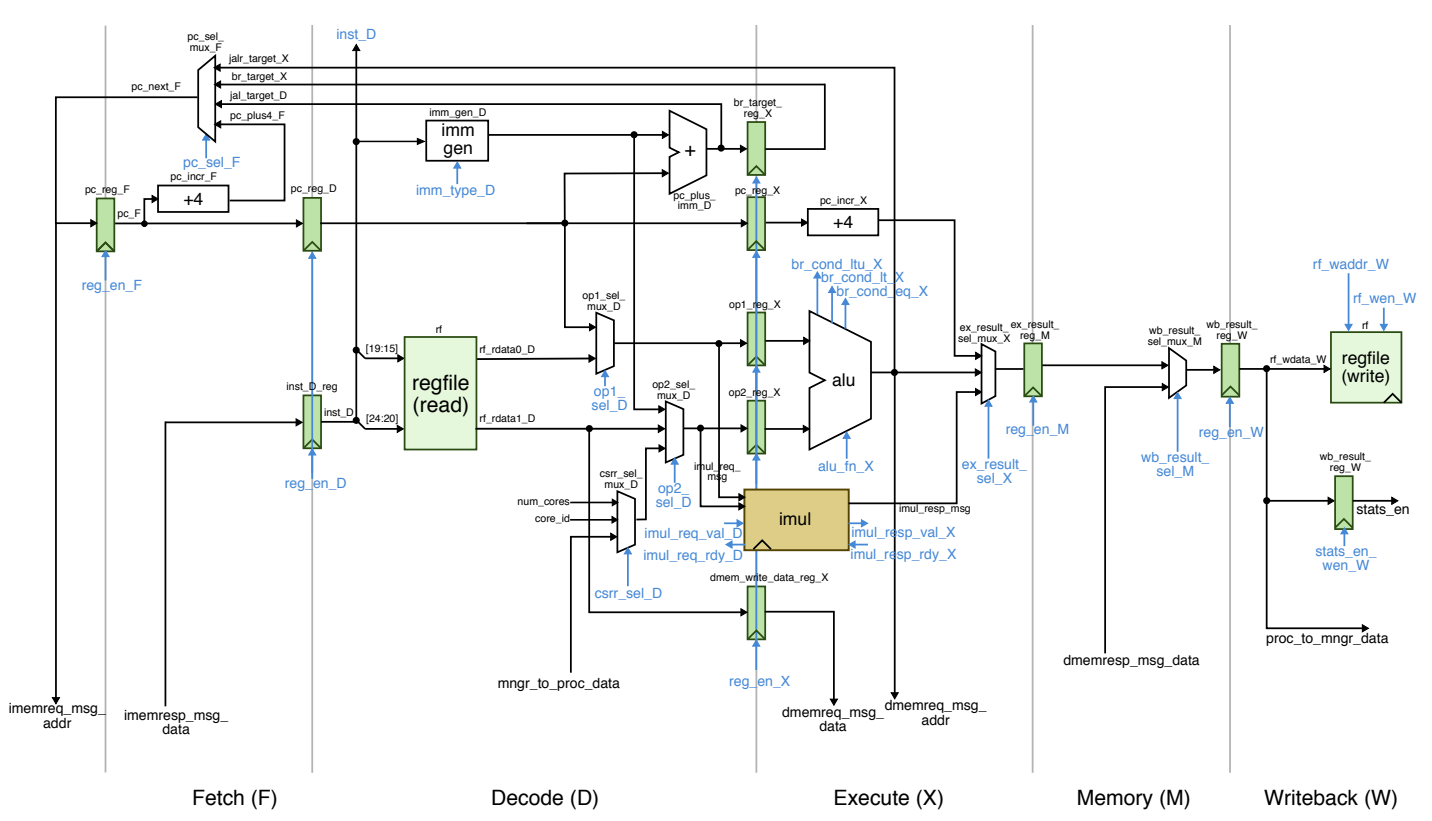
- Five-Stage Pipeline: Our design implements a classic five-stage processor pipeline with Fetch (F), Decode (D), Execute (X), Memory Access (M), and Write Back (W) stages.
- Baseline and Alternative Designs: The processor comes in two versions. The baseline design includes basic stalling for handling hazards, while the alternative design incorporates both stalling and bypassing mechanisms for efficient hazard resolution.
- TinyRV2 ISA Support: The processor supports the TinyRV2 instruction set architecture, aligning with modern processor design standards.
Features
- Stalling: In the baseline design, the processor stalls in the presence of data hazards, ensuring data integrity at the cost of reduced efficiency.
- Bypassing: The alternative design uses bypassing (forwarding) to resolve data hazards, significantly improving performance by reducing stalls.
- Modularity and Hierarchical Design: The processor’s architecture demonstrates a modular approach with encapsulated components, ensuring ease of understanding and modification.
 —
—
Cache System
Design
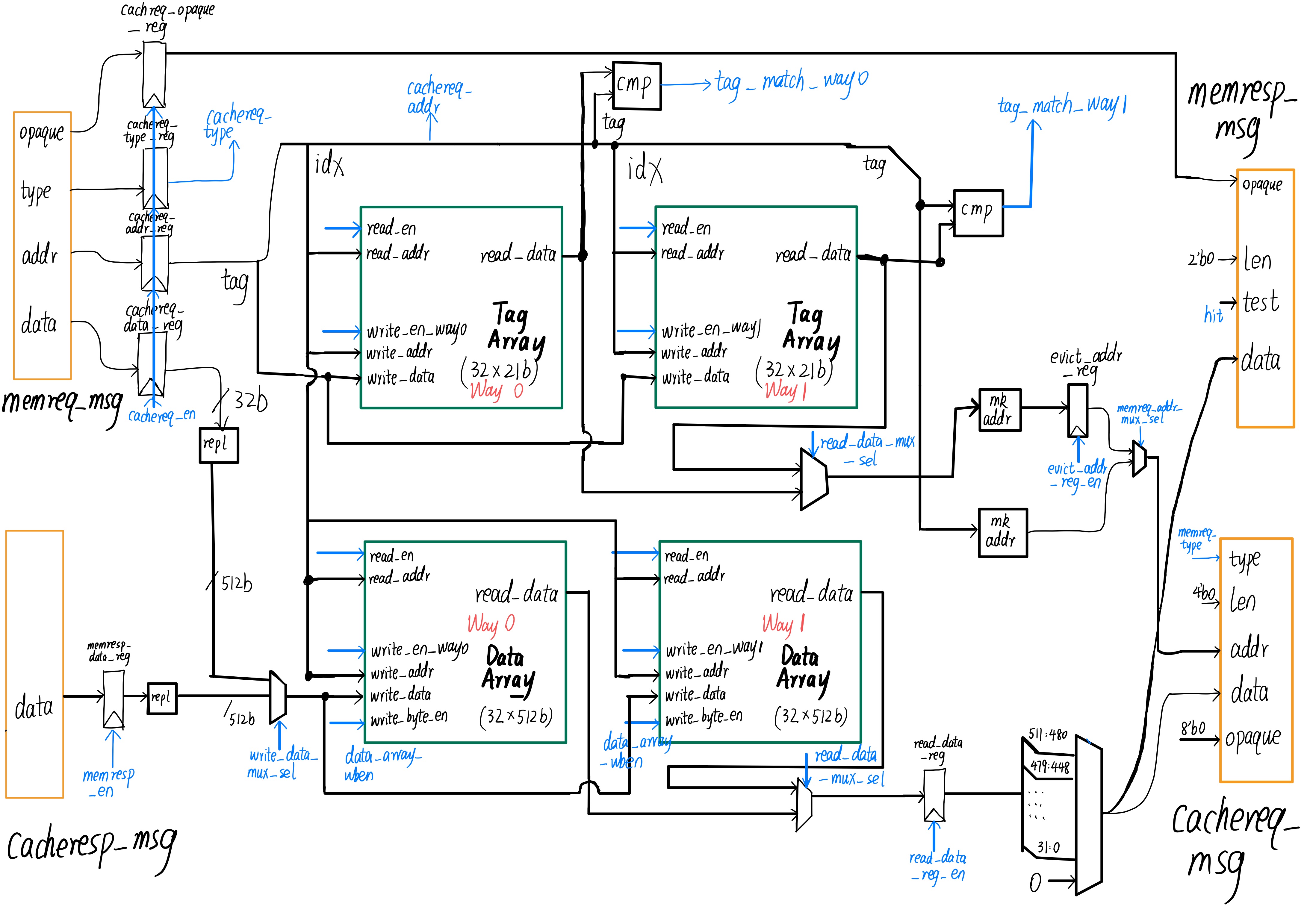
- Two Variants: The design includes two types of caches - an instruction cache and a data cache.
- Baseline Cache: A 2kB direct-mapped cache with 64-byte lines.
- Alternative Cache: A 2-way set-associative cache with 4kB capacity and 64-byte lines, implementing a Least Recently Used (LRU) policy.
Features
- Direct-Mapped and Set-Associative: The baseline cache provides simplicity and speed, while the alternative cache offers improved performance in diverse access patterns.
- Efficient Memory Access: Both cache designs aim to reduce the average memory access time, enhancing the overall speed of the processor.
- LRU Policy: The alternative design’s LRU policy ensures efficient utilization of cache space, prioritizing the retention of frequently accessed data.
 —
—
Branch Prediction
Design
- Three Models: The branch prediction component includes three models - Bimodal, Global, and GShare, each offering different prediction strategies based on branching history.
- Page History Table (PHT): A key element in all three models, used to store and update branching outcomes.
Features
- Adaptive Prediction: Each predictor adapts its strategy based on past branch behavior, improving prediction accuracy over time.
- Optimized for Various Scenarios: The different models offer flexibility, allowing the processor to optimize branch prediction based on specific use cases and program behaviors.
Integration and Synchronization
Combined Architecture
- Seamless Integration: The processor pipeline, cache system, and branch predictor are integrated into a cohesive unit, ensuring smooth data flow and efficient operation.
- Synchronization: Careful synchronization between pipeline stages, cache accesses, and branch prediction decisions is maintained to avoid conflicts and ensure data consistency.
Performance Optimization
- Data Flow Efficiency: The integration allows for optimized data flow, with the cache system reducing memory access times and the branch predictor minimizing control hazards.
- Adaptive Performance: The processor can adapt its operation based on workload characteristics, leveraging the strengths of each component for optimal performance.
Conclusion
The integrated design of this processor architecture represents a significant step in high-performance computing. By combining a sophisticated pipeline structure with an advanced cache system and versatile branch prediction models, the processor is capable of handling a wide range of applications efficiently. This design is a testament to modern processor design principles, balancing performance, complexity, and power consumption.